Hi there! I’m Sina, and this is my first ever post on my blog! Hope you enjoy it and learn some cool stuff!
In this blog post series, we are going to see how we can deploy and configure Apache Kafka on Kubernetes, produce and consume messages from a Go application to a Scala application and monitor our Kafka cluster with Prometheus and Grafana. So sit back, relax and enjoy, as we are going to learn some exciting stuff 🙂
We’re going to cover all these in a three part blog post:
- Part 1: Creating and Deploying a Strimzi Kafka Cluster on Kubernetes
- Part 2: Creating Producer and Consumer using Go and Scala and deploying on Kubernetes
- Part 3: Monitoring our Strimzi Kafka Cluster with Prometheus and Grafana
Introduction
When you Google “deploying Kafka on Kubernetes”, you may encounter so many different deployment approaches and various Kubernetes yaml files on the internet. After trying some of them and putting time on creating a fully working cluster and fixing problems, you realize that using Kafka on Kubernetes is hard! But don’t you worry, Strimzi is here to help!
Strimzi uses Kubernetes Operator pattern to simplify the process of configuring and running Kafka on Kubernetes. In case that you don’t know what an Operator pattern is, the Kubernetes documentation explains it very well:
Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop.
The Operator pattern aims to capture the key aim of a human operator who is managing a service or set of services. Human operators who look after specific applications and services have deep knowledge of how the system ought to behave, how to deploy it, and how to react if there are problems.
People who run workloads on Kubernetes often like to use automation to take care of repeatable tasks. The Operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides.
Kubernetes, Operator Pattern
Before diving into YAML files, let’s talk a little about Strimzi features and how it can help us.
What is Strimzi?
Strimzi provides container images and Operators for running Kafka on Kubernetes. These Operators are fundamental to the running of Strimzi and are built with specialist operational knowledge to effectively manage a Kafka cluster.
Strimzi Operators can simplify many Kafka related processes including: deploying, running and managing Kafka cluster and components, configuring and securing access to Kafka, creating and managing topics and users, etc.
The Strimzi deployment of Kafka includes many components which most of them are Optional. A typical Strimzi deployment might include:
- Kafka. A cluster of Kafka broker nodes
- ZooKeeper. Storing configuration data and cluster coordination
- Kafka Connect. An integration toolkit for streaming data between Kafka brokers and external systems using Connector (source and sink) plugins. (Also supports Source2Image)
- Kafka MirrorMaker. Replicating data between two Kafka clusters, within or across data centers.
- Kafka Bridge. Providing a RESTful interface for integrating HTTP-based clients with a Kafka cluster without the need for client applications to understand the Kafka protocol
- Kafka Exporter. Extracting data for analysis as Prometheus metrics like offsets, consumer groups, consumer lag, topics and…
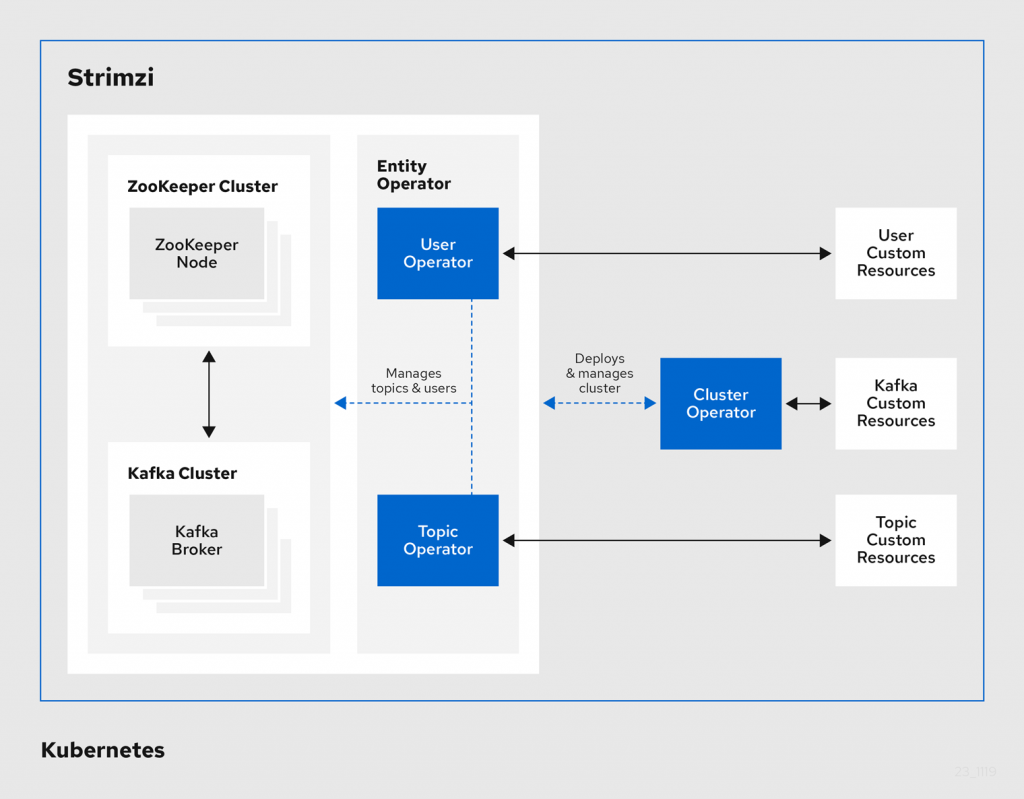
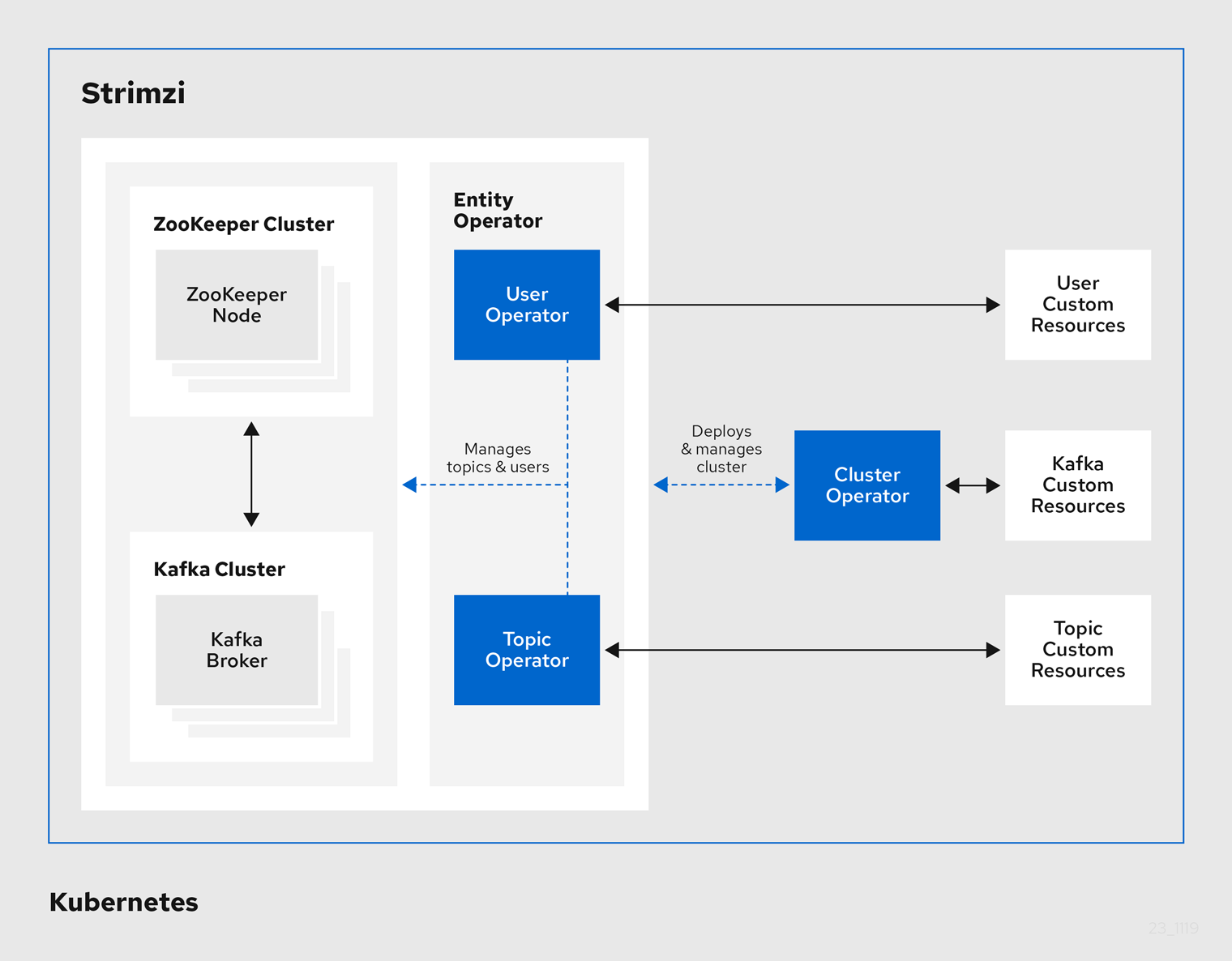
Strimzi Operators
As we have already mentioned, with Strimzi Operators, you no longer need to configure and manage complex Kafka related tasks and these Operators will do the hard work for you!
There are four types of Operators in Strimzi:
- Cluster Operator. Deploys and manages Apache Kafka clusters, Kafka Connect, Kafka MirrorMaker, Kafka Bridge, Kafka Exporter, and the Entity Operator
- Entity Operator. Comprises the Topic Operator and User Operator
- Topic Operator. Manages Kafka topics.
- User Operator. Manages Kafka users.
The Cluster Operator can deploy the Topic Operator and User Operator as part of an Entity Operator configuration at the same time as a Kafka cluster.
{kind=link}
Check out the Strimzi documentations for more details. Now, let’s see how we can deploy a Kafka cluster using Strimzi.
Deploying Kafka using Strimzi
For this tutorial, we are going to use Minikube. In order to create our Kafka cluster, we need to deploy yaml files in a specific order:
- Deploying the Cluster Operator to manage our Kafka cluster
- Deploying the Kafka cluster with ZooKeeper using the Cluster Operator. Topic and User Operators can be deployed in this step with the same deploy file or you can deploy them later.
- Now you can deploy other components as you like (Optional):
- Topic and User Operators
- Kafka Connect
- Kafka Bridge
- Kafka MirrorMaker
- Kafka Exporter and monitoring metrics
- …
Now, lets see how we can complete each step.
Deploying the Cluster Operator
First and foremost, let’s deploy the Cluster Operator. The Cluster Operator is responsible for deploying and managing Apache Kafka clusters within a Kubernetes cluster.
When the Cluster Operator is running, it starts to watch for creation and updates of the Kafka resources. We can configure the Cluster Operator to watch single, multiple or all namespaces for Kafka resources.
Be aware that deploying Cluster Operator requires a Kubernetes user account that has permission to create CustomResourceDefinitions, ClusterRoles and ClusterRoleBindings. Now… let’s get started!
First, create a namespace for the Cluster Operator in Kubernetes:
$ kubectl create ns kafka
Download the latest Strimzi package from their Github release page. This package contains Strimzi docs, deployment files and lots of examples. Navigate to install/cluster-operator folder which contains the Cluster Operator deployment files. After that, follow the below procedure:
First, we need to edit Strimzi installation files to use our kafka namespace. The default namespace inside the files is myproject. This needs to be changed to kafka. So change myproject namespace to kafka inside /install/cluster-operator/*RoleBinding*.yaml files. If you’re on Linux or MacOS, you can use the sed command to apply this change automatically (commands are taken from Strimzi document):
Linux:
$ sed -i 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
MacOS:
$ sed -i '' 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
As we have said before, we can configure the Cluster Operator to watch for single/multiple/all namespace(s).
Single Namespace
If you just want to deploy your Kafka Cluster in the same namespace as the Cluster Operator, no need to do anything else. Just deploy all yaml files from the cluster-operator folder. If you still want your Cluster Operator to watch only a single namespace but want your Kafka Cluster to reside in a different namespace, follow the approach presented in the Multiple Namespaces section.
Multiple Namespaces
Sometimes, we want to have multiple Kafka Clusters on different namespaces. So we need to tell the Operator the location of our Kafka Clusters (Kafka resources). Open 060-Deployment-strimzi-cluster-operator.yaml file and locate the STRIMZI_NAMESPACE environment variable. Change valueFrom to value and add your namespaces like below:
# ...
env:
- name: STRIMZI_NAMESPACE
value: kafka-cluster-1,kafka-cluster-2,kafka-cluster-3
# ...After that, you need to install RoleBindings for each namespace listed in the value field. Run the below commands for each of the watched namespaces (change watched-namespace to kafka-cluster-1 and run the commands, then change to kafka-cluster-2 and run, and so on…). Don’t forget that you have to create your namespaces in Kubernetes before running these commands.
$ kubectl apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace $ kubectl apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace $ kubectl apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespace
As I have already mentioned, if you want to use only a single namespace but want to deploy your Kafka Cluster in another namespace, use the same approach but with only one namespace. Now, you’re done and you can deploy your Cluster Operator.
All Namespaces
For watching all namespaces, just like above, Open 060-Deployment-strimzi-cluster-operator.yaml file and locate the STRIMZI_NAMESPACE environment variable. Change valueFrom to value and use “*” as the value:
# ...
env:
- name: STRIMZI_NAMESPACE
value: "*"
# ...Now, create ClusterRoleBindings that grant cluster-wide access for all namespaces to the Cluster Operator. Replace my-cluster-operator-ns to the namespace which you want the Cluster Operator to be deployed (in our case, it should be kafka namespace)
$ kubectl create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-cluster-operator-ns:strimzi-cluster-operator $ kubectl create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-cluster-operator-ns:strimzi-cluster-operator $ kubectl create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-cluster-operator-ns:strimzi-cluster-operator
Now, we are ready to deploy our Cluster Operator:
$ kubectl apply -f install/cluster-operator -n kafka
Verify that the Cluster Operator was successfully deployed and ready:
$ kubectl get deployments -n kafka NAME READY UP-TO-DATE AVAILABLE AGE strimzi-cluster-operator 1/1 1 1 40m
For Deploying the Cluster Operator using Helm Chart and OperatorHub.io, check out the Strimzi documentation.
So, our Cluster Operator is running. Now, lets deploy our Kafka Cluster.
Deploying the Kafka Cluster
There are two approaches to deploy a Kafka Cluster:
- Ephemeral Cluster. An ephemeral cluster is a Cluster with temporary storage which is suitable for development and testing. This deployment uses emptyDir volumes for storing broker information (for ZooKeeper) and topics or partitions (for Kafka). So all the data will be removed once the Pod goes down.
- Persistent Cluster. Uses PersistentVolumes to store ZooKeeper and Kafka data. The PersistentVolume is claimed using a PersistentVolumeClaim to make it independent of the actual type of the PersistentVolume. Also, the PersistentVolumeClaim can use a StorageClass to trigger automatic volume provisioning.
Check out the /examples/kafka folder for various examples of both cluster types. Now, let’s investigate different properties of a Kafka deployment file together.
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster #1
spec:
kafka:
version: 2.6.0 #2
replicas: 1 #3
resources: #4
requests:
memory: 4Gi
cpu: "1"
limits:
memory: 4Gi
cpu: "2"
jvmOptions: #5
-Xms: 3276m
-Xmx: 3276m
listeners: #6
- name: plain
port: 9092
type: internal
tls: false
- name: external
port: 9094
type: nodeport
tls: false
config: #7
auto.create.topics.enable: "true"
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
log.message.format.version: "2.6"
log.retention.hours: 1
storage: #8
type: persistent-claim
size: 2Gi
class: standard
deleteClaim: false
logging: #9
type: inline
loggers:
kafka.root.logger.level: "INFO"
zookeeper: #10
replicas: 1
storage:
type: persistent-claim
size: 2Gi
class: standard
deleteClaim: false
resources:
requests:
memory: 2Gi
cpu: "1"
limits:
memory: 2Gi
cpu: "1.5"
logging:
type: inline
loggers:
zookeeper.root.logger: "INFO"
entityOperator: #11
topicOperator: {}
userOperator: {}- Name of your Kafka cluster.
- The Kafka version. In case of upgrading, checkout the Upgrading Procedure from the Strimzi documentation
- Configuring the number of the Kafka broker nodes
- Setting container resource constraints.
A request is the amount of the resource that the system will guarantee. Kubernetes decides on which node to put the Pod based on the request values.
A limit is the maximum amount of resources that the container is allowed to use. If the request is not set, it defaults to limit. And when the limit is not set, it defaults to zero (unbounded). - Specifies the minimum (-Xms) and maximum (-Xmx) heap allocation for the JVM
- Listeners configure how clients connect to a Kafka cluster. Multiple listeners can be configured by specifying unique name and port for each listener.
Two types of listeners are currently supported which are Internal Listener (for accessing the cluster within the Kubernetes) and External Listener (for accessing the cluster from outside of the Kubernetes). TLS encryption can also be enabled for listeners.
Internal listeners are specified using an internal type. And for external types, these values can be used:- route. to use OpenShift routes and the default HAProxy router
- loadbalancer. to use loadbalancer services
- nodeport. to use ports on Kubernetes nodes (external access)
- ingress. to use Kubernetes Ingress and the NGINX Ingress Controller for Kubernetes.
- You can specify and configure all of the options in the “Broker Configs” section of the Apache Kafka documentation apart from those managed directly by Strimzi. Visit the Strimzi documentation for the forbidden configs.
- Storage is configured as ephemeral, persistent-claim or jbod.
- Ephemeral. As we have discussed previously, an Ephemeral cluster uses an emptyDir volume. The data stored in this volume will be lost after the Pod goes down. So this type of storage is only suitable for development and testing. When using clusters with multiple ZooKeeper nodes and replication factor higher than one, when a Pod restarts, it can recover data from other nodes.
- Persistent Claim. Uses Persistent Volume Claims to provision persistent volumes for storing data. a StorageClass can also be set to use for dynamic volume provisioning. Also, we can use a selector for selecting a specific persistent volume to use. It contains key:value pairs representing labels for selecting such a volume. Check out the documentation for more details. In Minikube, a default StorageClass with the name “standard” has been configured automatically and we can use it like above.
- JBOD. By using jbod type, we can specify multiple disks or volumes (can be either ephemeral or persistent) for our Kafka cluster.
- Loggers and log levels can be specified easily with this config.
- ZooKeeper configurations can be customized easily. Most of the configurations are similar to the cluster configs. Some options (like Security, Listeners, etc.) cannot be customized since the Strimzi itself is managing them.
- The Entity Operator is responsible for managing Kafka-related entities in a running Kafka cluster. It supports several sub-properties:
- tlsSidecar. Contains the configuration of the TLS sidecar container, which is used to communicate with ZooKeeper.
- topicOperator. contains the configuration of the Topic Operator. When this option is missing, the Entity Operator is deployed without the Topic Operator. If an empty object ({}) is used, all properties use their default values.
- userOperator. contains the configuration of the User Operator. When this option is missing, the Entity Operator is deployed without the User Operator. If an empty object ({}) is used, all properties use their default values.
- template. contains the configuration of the Entity Operator pod, such as labels, annotations, affinity, and tolerations
Note that the ZooKeeper cluster that gets deployed automatically with our Kafka Cluster cannot be exposed to other applications. But there’s a (not recommended) workaround:
This is intentional. We do not want third party applications use the Zookeeper because it could have negative impact on Kafka cluster availability and because Zookeeper is quite hard to secure. If you really need a workaround, you can use this deployment which can proxy Zookeeper (it expects your Kafka cluster to be named my-cluster – if you use different name you should change it in the fields where my-cluster is used). Afterwards you should be just able to connect to zoo-entrance:2181.
scholzj, Strimzi Github
Now, let’s deploy the Kafka resource into our kafka namespace (you can use a different namespace for your Kafka cluster as explained above)
$ kubectl apply -f kafka-deployment.yaml -n kafka
Like before, verify that the Kafka cluster has been deployed successfully:
$ kubectl get deployments -n kafka
Managing Topics
Now that our Kafka cluster is up and running, we need to add our desired topics. By using the Topic Operator, we can easily manage the topics in our Kafka cluster through Kubernetes resources. These resources are called KafkaTopic.
The Topic Operator watches for any KafkaTopic resources and keeps them in-sync with the corresponding topics in the Kafka cluster. So if a KafkaTopic gets created, updated or deleted, the Topic Operator reflects these changes to the Kafka cluster. Also, the Topic Operator also watches for any direct changes to the topics inside the Kafka cluster. This means that if any topic gets created, updated or deleted directly inside the Kafka cluster, The Topic Operator also creates, updates or changes the KafkaTopic resources respectively.
As you may have notices, we have set the auto.create.topics.enable parameter to “true” inside our Kafka resource. So there’s no need to create a topic manually and the Topic Operator creates the KafkaTopic resource for us. But it doesn’t hurt to manage the topics ourselves and also it’s a best practice. Now, let’s create a topic with the name of my-topic:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 3
replicas: 1
config:
retention.ms: 7200000
segment.bytes: 1073741824We can easily create and configure our topic with a KafkaTopic resource. Now deploy the KafkaTopic resource like other resources with apply command.
Testing our Kafka Cluster
We have created our Kafka Cluster inside Kubernetes. Now, it’s time to test it.
There are two scripts inside the Kafka binary which we can used to test a Kafka Cluster.
- kafka-console-producer for producing messages.
- kafka-console-consumer for consuming messages.
These two scripts are also available inside the Strimzi docker image and we can use them to test our Kafka cluster from inside the Kubernetes (internal listener):
- Get the DNS name of the Kafka Cluster service in order to connect to it:
$ kubectl get svc -n kafka

You can access a service by its DNS name:
<service.name>.<namespace.name>.svc.cluster.local
The “svc.cluster.local” can be omitted in our case. If you are accessing the service from its own namespace (kafka namespace as we used in this post), you can access the Kafka cluster by its service name only: my-cluster-kafka-bootstrap:9092.
But if you are accessing it from outside of its namespace, you need to include the namespace to the DNS name too: my-cluster-kafka-bootstrap.kafka:9092
- Run a Kafka producer and write some texts on the console after connecting to send to the topic:
$ kubectl run kafka-producer -ti --image=strimzi/kafka:0.20.0-rc1-kafka-2.6.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list my-cluster-kafka-bootstrap.kafka:9092 --topic my-topic
Note: if we include -n kafka right after the kubectl command, you can omit the namespace from the service address: –broker-list my-cluster-kafka-bootstrap:9092.
- Type a message into the console where the producer is running and press Enter. The message should be in my-topic now. Now, we need a consumer to consume the message.
- Run a Kafka consumer:
$ kubectl run kafka-consumer -ti --image=strimzi/kafka:0.20.0-rc1-kafka-2.6.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap.kafka:9092 --topic my-topic --from-beginning
- Now, you should see the consumed message on the console!
If you have added an external listener (like nodeport) to your Kafka Cluster and want to test it from outside of the Kubernetes, follow these steps:
- Download the latest binary release of Kafka from here.
- Get the IP of the minikube by running minikube ip command (mine is 192.168.99.105).
- Run kubectl get svc -n kafka and find the exposed port of the kafka-external-bootstrap (highlighted with blue in the picture above)
- The kafka-console-producer and kafka-console-consumer are in the /bin directory of the downloaded package (for Windows, navigate to /bin/windows)
- Like above, fire up your console producer and consumer with the below commands (Windows commands are the same) and test your cluster from outside of the Kubernetes:
$ kafka-console-producer.sh --broker-list 192.168.99.105:30825 --topic my-topic
$ kafka-console-consumer.sh --bootstrap-server 192.168.99.105:30825 --topic my-topic --from-beginning
Conclusion
Strimzi provides a nice abstraction over the complicated configs of a Kafka Cluster on Kubernetes. It takes a small amount of time to deploy a fully working cluster. Also, it has an extensive amount of configurations so you can deploy your cluster in any way you like.
Now that we have a fully working Kafka cluster in our Minikube, it’s time to write some code and use it. In part 2 of this series, we’ll go through creating a producer and consumer and deploying them on Kubernetes.
Feel free to ask any questions or share any comments in the comment section or contact me via email. Thanks for reading. See you in Part 2!
[…] the steps to deploy Strimzi on Kubernetes since we have explained it before in another blog post. Check it out from this link (Make sure to get the latest version of Strimzi from their website. I have used an older version in […]
Hi Sina,
Thanks for your post. I have setup strimzi kafka and flink on the namespaces, but facing issues while consuming the kafka messages in flink. I tried two ways:
1 – loadbalancer type: With this, when I do “minikube tunnel”, I’m able to publish messages to the kafka topic from a sample java code and also from the console scripts. While trying to consume the same in flink, I see exceptions.
2 – nodeport type: With this, I’m not able to publish messages to kafka topic using console commands as well as through the java code also. I used same DNS and port as you mentioned above. Also, strmizi operator service keeps crashing as http://17*.**.*.**:8080 connection refused. Did you port forward any service for this?
Can you explain, how did you add an external listener to your kafka cluster?